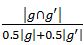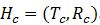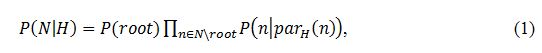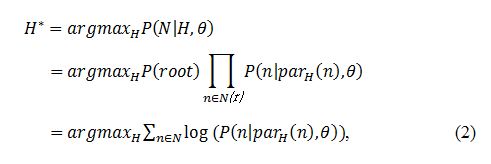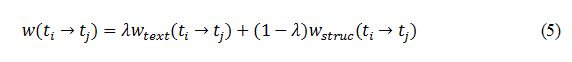随着信息化发展,人们急切需要有效的新闻文章组织方式,让日常的新闻阅读变得轻松便捷。已有的研究方法如话题模型能够将新闻文章按照不同话题进行聚类,然而这类无监督的模型得到的话题类语义不明确,准确率低。本文提出了一种对特定类的新闻事件构建高质量层次话题模板的方法,为新闻的层次分类提供依据,也方便了人们对这类新闻事件的总体认识。具体来说,本文利用了新闻事件对应的的目录结构(蕴含话题层次),通过对一类事件的维基页面的目录进行融合,得到这类新闻事件的层次话题模板结构。实验证明,与基线方法对比,我们方法在线%的提高。 随着国家信息化的飞速发展,在线新闻阅读已经变们获取信息的重要来源之一。然而当一个事件发生时,来自不同的新闻蜂拥而至,人们迫切需要一种有效的新闻组织方式,方便自己找到感兴趣的新闻内容。已有的研究主要利用话题模型如LDA(Latent Dirichlet Allocation)挖掘新闻的话题,并将新闻按照话题进行聚类。然而,这类模型是无监督的,得到的新闻话题没有明确的语义,新闻聚类的准确度不高。本文提出了一种利用构建新闻事件话题层次模板的方法,为新闻层次分类提供了依据,也为用户提供了关于这类事件的概览。 作为一种并由世界各地的人们通过互联网合作编写的百科全书,提供了大量的高质量的信息:数以千万计的维基页面涵盖了各种事物和概念。如今,中文、百度百科和互动百科作为最流行的中文在线知识库,收录了累计将近3000万条中文条目 。除了被用以获取人们所需知识外,它还被广泛地应用在知识获取研究中。页面的信息框包含了结构化的属性-属性值信息,被用于属性抽取和知识图谱构建[1][2]。
然而,除了信息框,维基页面的目录表也提供了不同粒度的层次线海地地震”维基页面“目录”中每个标签代表了一个话题,其对应的文本描述就是对话题的相关描述。目录的层级关系代表了话题之间的层次关系。中有大量的包含这些高质量的话题信息的新闻事件页面,我们可以利用相似新闻事件的维基页面构建这类新闻事件的层次话题模板。这样的层次话题模板不仅对这一类事件(如地震事件)的所有话题及话题之间的关系进行了总结,而且对于搜索与浏览、信息组织和检索等应用也有很大帮助[6]。虽然中也有类别(如地震)对应的维基页面,但是该页面的目录所蕴含的层次话题是粗糙的并且不完整的。利用大量不同的具体事件(如2010海地地震,2010智利地震等)对应的维基页面构建关于该类事件(地震类事件)的层次话题使得信息相互补充,能够得到更高质量更全面的层次话题模板。 融合多个维基页面的目录结构构建层次话题模板常具有挑战的。首先,不同的维基页面目录的话题标签可能表示相同的话题,如:“国外援助”和“来自其他国家的援助”。其次,不同维基页面目录的话题-子话题的关系可能存在冲突。如“灾后情况”-“响应”和“响应-灾后情况”。最后如何同时利用已有的话题标签之间的结构信息和话题标签的描述文本信息? 本文,我们提出了一个新的构建高质量层次话题模板的方法。我们用贝叶斯网络对层次话题进行建模,将构建层次话题的问题转变为结构学习问题。通过同时考虑结构信息和文本信息,提高了层次话题的精度。实验证明我们的方法比基线方法在层次线.问题定义 定义 3.层次话题模板。对于类别c,融合其包含的所有维基页面对应的层次话题得到的最终层次话题结构为该类别的层次话题模板H_c=(T_c,R_c),其中T_c={t}是话题集合,R_c表示这些话题之间的层次关系。注意,由于是众包的,话题t可能对应不同维基页面的多个话题标签。层次话题模板以c为根节点。 本小节介绍了将不同维基页面的话题标签聚类得到最终层次话题模板中的话题的方法。考虑到同一个维基页面的话题标签通常是被人们用来表示不同的话题,因此我们采用了一种带约束的增量聚类算法(CIC, Constrained Incremental Clustering),只将不同页面的话题标签进行聚类。当然,很多已有的其他聚类算法如kmeans等也可以用来做话题标签聚类,由于我们的重点是后面一步得到话题层次关系,因此我们对此不过多讨论。 增量聚类算法主要基于相似度,通过计算话题标签和已有标签类的相似度,将标签放到相似度最大(并且大于一定阈值δ)的标签类,否则该标签单独成为一个新的类。计算两个话题标签的相似度可以考虑以下几个因素:词汇相似度。每一个话题标签g是由一些单词构成的序列所组成的短语,我们可以将g堪称是单词集合,通过如下方法来计算两个标签g和g^的词汇相似度:
综上,考虑所有因素,我们对所有相似度加权平均得到两个标签的最终的相似度值。基于标签相似度的计算,计算话题标签g和一个话题标签类t之间的相似度sim(g,t)有三种不同的方式:1)最近距离:取标签g与t中所有话题标签相似度最小的值作为两者相似度;2)最远距离:取标签g与t中所有话题标签相似度最大的作为两者相似度;3)平均距离:取取标签g与t中所有话题标签的相似度平均值的作为两者相似度。通过实验,我们发现取最远距离方式能取得最好的聚类效果。 一个基本的方法是构建一个有向完全图,图中的每个节点代表一个话题,话题之间的有向边(如t_i→t_j)表示子话题关系(t_j是t_i的自话题),每条边赋予权值。基本的权值计算方法是将每个维基页面的话题标签用其所属话题替代,将包含该边所蕴含子话题关系的维基页面数量当成该边的权重。 最后利用基于图的最大生成树算法 Chu-liu/Edmonds [3]构建最大生成树,最后得到的树形结构即为我们最终的层次话题模板H_c=(T_c,R_c)。Chu-liu/Edmonds是一个算法,主要有两步:第一步是选择入边,第二步是打破环状结构。我们了一个最重入边集M,一开始M为空。Chu-liu/Edmonds算法选择任意一个在入边集中没有入边的节点,找到该节点的最重入边,并加入到M。重复该步骤直到M中出现环,然后将环看成是一个伪节点,继续往M中加入最重入边,直到没有点剩下,通过移除环中的最小权重边打破环。具体算法可以参考文献[3]。
然而上述这种方法有一个问题。考虑以下情况:如果1-3在维基文章中出现5次,2-3出现2次,而1总共出现50次,而2总共只出现2次,那么我们更倾向于2-3(置信度: 2/2=1)而不是基本方法得到的最终得到的结果1-3(置信度: 5/50=0.1)。在下一节中我们将用一个概率的方法来解决这个问题。 我们考虑将一个层次话题结构看成是一个贝叶斯网络,话题是网络中的节点变量,那么给定层次结构H,该网络的联合概率分布可以写成:
其中n(t_i→t_j)是包含关系t_i→t_j的维基页面数,而n(t_i )是包含话题t_i的维基页面数。α是平滑系数,防止分母为0。 考虑文本信息:考虑到每个话题包含的话题标签都有一段文本描述,把所有标签的文本描述聚集到一起是该话题对应的文本描述。我们可以把每个话题的文本描述当成一个词袋,这样每个话题可以表示成在词上的分布,φ_t=〖{φ_(t,w)}〗_(w∈V), s.t. ∑_(w∈V)?〖φ_(t,w)=1〗。为了捕获子话题关系,我们期望子话题的分布的期望等于父亲话题的分布,即E(φ_(t_j ) )=φ_(t_i )。这就自然地导致了层次狄利克雷分布,即φ_(t_j ) φ_(t_i )~Dir(βφ_(t_i )), 其中β是聚集参数。这样,我们能够得到:
。这样能够解决基本方法存在的问题,然而却没有考虑重要的话题文本描述信息。因此,我们将公式(4)带入公式(2)可以计算基于文本的权重 本文通过和人工构建的标准集进行对比来检验所提出的层次话题模板构建方法。我们首先测试本文提出的话题标签聚类算法CIC,然后测试层次话题模板的准确度。实验代码已经公开在GitHub上:。
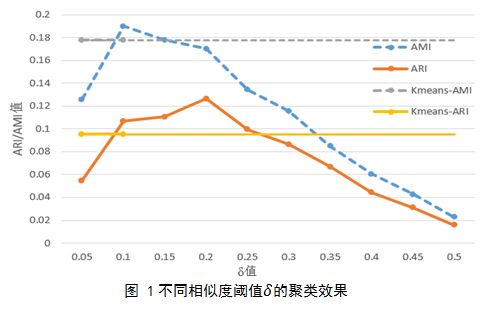
我们在三个真实数据集上评估了我们的方法。这三个数据集分别是英文维基类别“地震”和“选举”,中文维基类别“地震”。三个数据集包含了293,60和48篇相关维基页面。去掉噪音话题标签如“参考文献”、“引用”、“相关链接”等,三个数据集分别包含463,426和79个话题标签。我们首先评估CIC的聚类效果,之后我们评估层次话题模板的准确度。 实验采取加权平均的方式对词法、上下文语义以及wordnet相似度三种相似度特征进行加权平均。实验发现权重分别取0.2,0.7和0.1时,采用最远距离方式计算一个话题标签到一个话题标签类的距离能够得到最优的聚类结果。在这些参数设置下,实验在图1中给出了对于不同的阈值δ数据集一(英文地震数据集)的聚类评价。当δ=0.1时AMI最大,当δ=0.2时ARI值最大,然而在δ=0.1时两个值都要超过K-means算法取得的结果。因此我们可以去取阈值为0.1,对于另外两个数据集,我们用相同的方法可以确定为阈值分别取0.2和0.25。聚类之后,三个数据集分别有176, 112和57个话题。实验证明了我们提出的CIC聚类方法的有效性,并且优越于K-means算法。 同样地,我们通过人工标注构建了标准层次话题模板。我们找了三个大学生进行标注,每个子话题关系必须两个人确定才被采用。一个简单的标注方法是,给定我们生成的层次话题模板,让三个标注者进行修改得到最终的层次话题模板。本节从准确率、召回率两方面对基于贝叶斯网络的层次话题模板进行评估。 本文使用R_c和R_S来分别表示实验结果的子话题关系集合和标准的层次话题模板的子话题关系集合。由于R=R_s ,因此准确率=召回率=F1=R_c 〖∩R〗_s /R 。 我们对比三种方法,一种是基本方法Basic,一种是我们提出的只考虑结构信息的贝叶斯网络方法Baye+S,最后一种既考虑结构信息和文本信息的贝叶斯网络方法Baye+ST。
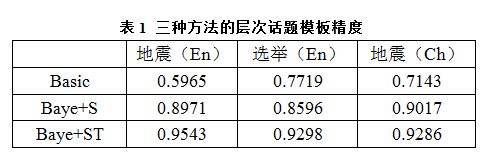
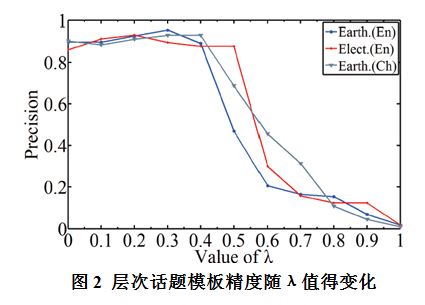
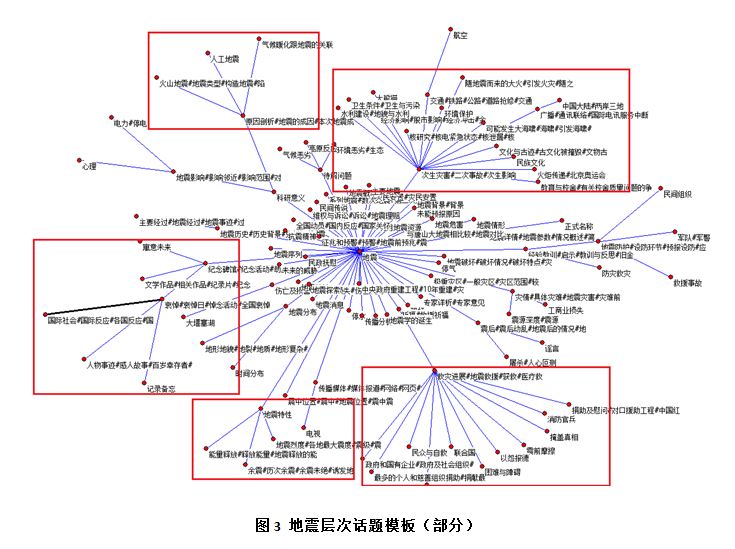
表1中给出了三个方法构建得到的层次话题模板的准确度,我们发现基于贝叶斯网络,既考虑结构信息又考虑文本信息的方法Baye+ST(取最好的λ值)显著好于只考虑结构信息的贝叶斯方法Baye+S(+24.3%,p0.025,t-test)和基本方法Basic (+5.1% p0.025,t-test)。对结构信息进行归一化的方法Baye+S也比直接利用结构信息的方法Basic显著提高了层次线)。 最后,我们在图3中展示了中文地震数据集上的层次话题模板。从中可以看到,根结点 “地震” 包含“次生灾害”、“救灾进展”、“地震特性”等子话题。话题“地震特性”的子话题“地震烈度”、“能量”等,“救灾进展”包含“与自救”、“困难与障碍”、“捐助及慰问”等。本文将这些提及的关系在图中用红线表示。总体而言,该地震层次话题模板符合人们的常识。
据我们所知,我们的研究问题是新的,还没有工作研究如何利用维基页面的目录结构来构建层次话题模板。已有的工作主要集中在如何从文本档中自动构建层次线],主要基于层次聚类方法[7]和层次线]。和这些工作不一样,我们利用了维基页面的目录以及目录中标签的文本描述信息。 我们的工作还和已经被大量研究的本体构建[4-5][13-15]不一样。本体构建主要是构建概念层次,是is-a关系,而不是话题上的层次关系。举例来说,给定“动物” 这个类别,他们是构建“猫”和“狗”这样的子类。而我们是构建“动物”和 “动物” 等这样的子话题。我们的工作对于人们了解一个不熟悉的类别有重要的意义,同时我们的工作还有助于提高信息检索等重要应用。
本文提出一个新的问题,即层次话题模板的构建,该问题旨在充分利用维基知识库,构建高质量层次话题模板。我们提出了一个新的方法既考虑了已有的结构关系和话题的文本信息来推导出最优层次话题结构。实验结果表明了方法的有效性。在今后的研究中,我们将研究如何随着新的维基页面的建立,自动得逐步更新层次话题模板。
|